Building a Large Language Model from scratch: A learning journey

What is this? I want to understand AI models not only as a user. I want to know how they're built, what's inside, how they are making the magic possible. I don't want to just consume, I want to know the ingredients and I want to be able to cook.
I will be going through Build a Large Language Model (From Scratch) book by Sebastian Raschka. My intention is to go through it daily: 2 hours per day on weekdays and 1 h/day on weekends, until I finish the book. Then I'll proceed to more hands-on projects to put this knowledge to use.
Why am I doing this? I was making notes for myself: to understand better, to see progress, to keep myself accountable. Then I came across this old tweet:

This page will be updated as I go, until I finish the book, and this is the summarization in my own words.
Who is the intended audience? It probably has the audience of one - just me. It's not a learning resource, as I'm only adding this that I want to remember or understand better. If something is obvious to me, I won't be adding it here. But maybe it could be useful for others too, if not for learning, then at least to see the process of someone learning from scratch and to get inspired to do the same.
Daily progress
Day 1 (Thu)
- Created this page.
- Started reading and learning.
- First step back before moving forward. I don't know PyTorch so I need to start with PyTorch basics in Appendix A before even starting Chapter 1.
Reading Appendix A, "Introduction to PyTorch"
Installed PyTorch, uv, pip, jupyter and ran a sample notebook in Jupyter. Everything works.
finished the day at page 261 of the book, because it's an appendix
Day 2 (Fri)
Continuing learning PyTorch.
p.279
Day 3 (Sat)
Finished PyTorch section.
PyTorch section summary
- PyTorch is NumPy but for tensors instead of arrays, plus differentiation and deep learning capabilities.
- Learned what tensors are: multi-dimensional arrays.
- Works well on GPUs, too bad my Linux machine doesn't have NVIDIA GPU and I have to run everything on an Intel CPU.
Finished reading Appendix A, "Intorduction to PyTorch".
Started Chapter 1: Understanding large language models
p.5
Day 4 (Sun)
LLMs are based on the transformer architecture. The key idea of the transformer architecture is an attention mechanism that gives the LLM selective access to the whole input sequence when generating the output one word at a time. Like reading a paragraph and instinctively focusing on the few words that tell you what it's really about.
The ability to perform tasks that the model wasn't explicitly trained to perform is called an emergent behavior. Translation was such a behavior for GPT models. It wasn't trained for that but was able to do it, based on vast data in different contexts. I wonder how many more emergent behaviors are still uncovered and will surprise us in the future.
Finished Chapter 1: Understanding large language models.
Started Chapter 2: Working with text data.
Embedding - the concept of converting data into a vector format.
An embedding is a mapping from discrete objects, such as words, images, or even entire documents, to points in a continuous vector space. The primary purpose of embeddings is to convert nonnumeric data into a format that neural networks can process.
We can embed different data types: video, audio, text. But different data formats require different embedding models.
p. 22
Day 5 (Mon)
Implementing a "toy" tokenizer to understand how tokenization works and its main concepts.
Byte-pair encoding (BPE) - when a word is not in a model's vocabulary, it allows the model to break down words that aren't in its predefined vocabulary into smaller subword units or even individual characters, enabling it to handle out-of-vocabulary words
p. 41
Day 6 (Tue)
Chapter 2: Working with text data
Embedding size = number of features per token In general, the more the better but needs to balance cost vs. slower training and wasted capacity.
In addition to token embeddings, positional embeddings are added for each token:
- The token embeddings (what each word means)
- The positional embeddings (how far along the sentence we are)
Full embedding process:
- Get input text
- Break it down into tokens
- Convert all tokens to token IDs
- Generate token embeddings of X size (X = number of dimensions / features per token)
- Generate positional embeddings of X size (same as token embeddings)
- Final input embeddings = token embeddings + positional embeddings
- Same vector size but enriched with positional data which will be important during training
Finished Chapter 2: Working with text data.
Started Chapter 3: Coding attention mechanisms
This is the attention part from Attention Is All You Need paper.
What's attention?
- The model looks at all the tokens in the input and decides which ones to focus on when processing a particular token.
- Example: When processing the word "it" in "The cat chased the dog because it was tired", the model needs to pay more attention to "cat", not "dog" or "because."
Self-attention is a mechanism that allows each position in the input sequence to consider the relevancy of, or "attend to", all other positions in the same sequence when computing the representation of a sequence.
- Cross-attention: one sequence attends to another sequence (decoder attends to encoder outputs)
- How do the words in this sentence relate to each other?
- Self-attention: each token attends to all tokens in the same sequence (including itself)
- How does the generated word relate to the input sentence?
Context vectors are calculated for each item of input to enrich representation of each element in an input sequence by adding information from all other elements in the sequence, to better understand relationship and relevance of words in a sentence to each other.
p.57
Day 7 (Wed)
The dot product is a way to measure how similar two vectors are.
- Calculated by multiplying two vectors element-wise and then summing the products
- Measures alignment - how much the two vectors point in the same direction in space
- If they point the same way → large positive dot product
- If they're perpendicular → dot product ≈ 0
- If they point opposite ways → large negative dot product
- The dot product is how the model decides which words are related (how much attention it should give to a given word)
Context vector = sum (each input vector x attention weight)
Important: at this point, all the calculated numbers (token embeddings, positional embeddings, weights) are just noise, all random. We're just setting the stage for what comes next, nothing makes sense yet. It all starts making sense during training stage, when backpropagation starts nudging those numbers in the right directions and showing the real context.
p.68
Day 8 (Thu)
Causal attention (also: masked attention)
- A special form of self-attention
- Restricts a model to only consider previous and current inputs in a sequence when processing any given token when computing attention scores, which is different from standard self-attention, which allows access to the entire input sequence at once.
- Explicitly masks attention weights in the attention matrix for tokens that come after the input token.
- Helps with learning to predict the next token effectively (essential for language models).
p.78
Day 9 (Fri)
Dropout - masking some % of the weights to prevent overfitting of data. Only used during training.
Multi-head attention - creating multiple instances of the self-attention mechanism, each with its own learned Q, K, and V projection weights, and then combining their outputs. Each head adds additional embedding dimensions to each token, focusing on different aspects of its meaning (during training).
p.91
Day 10 (Sat)
Started Chapter 4: Implementing a GPT model from scratch to generate text
p.98
Day 11 (Sun)
Training neural networks with many layers can be difficult due to vanishing or exploding gradients, making it difficult for the network to adjust its weights, meaning that the network has difficulties learning the underlying patterns in the data, which results in difficulties in making accurate predictions.
p.103
Day 12 (Mon)
Feed-forward module
- A small two-layer neural network applied to each token individually
- Lets each token transform its meaning after seeing context (ie. after applying attention)
It's a little frustrating to keep building a more and more complex model of matrices, added dimensions, weights, vectors, mathematical operations, and trying to see where and how the model (essentially, the LLM) actually "learns", only to repeatedly remind myself that all the "learning" will happen later, during backpropagation (short for "backward propagation of errors"), and everything before that is just the machinery that makes learning possible.
Maybe going backwards would be more logical and easier to understand? But I don't know how easy it would be to explain the concepts then and if it even makes sense. Anyway, back to building yet more complicated mental models that are nothing more than scaffolding yet, doing absolutely nothing, just more and more of evenly distributed randomness.
Feed Forward Network: for each token, take my token's vector, blow it up into a richer space (usually 4x?), apply a nonlinear transformation (GELU), then compress it back down (by 4x, so that the output is the same size as input) into a refined meaing.
Vanishing gradient problem - an issue where gradients (which guide weight updated during training) become progressively smaller as they propagate backwards through layers, making it difficult to effectively learn in earlier layers.
p.111
Day 13 (Tue)
Shortcut connections - creates an alternative, shorter path for the gradient to flow through the network by skipping one or more layers. They help preserve the flow of gradients during the backward pass in training. It's achieved by adding each layer's input to the nonlinear transformation of that input. This way the gradient doesn't become vanishingly smaller with each layout.
p.117
Day 14 (Wed)
Overview of GPT model architecture
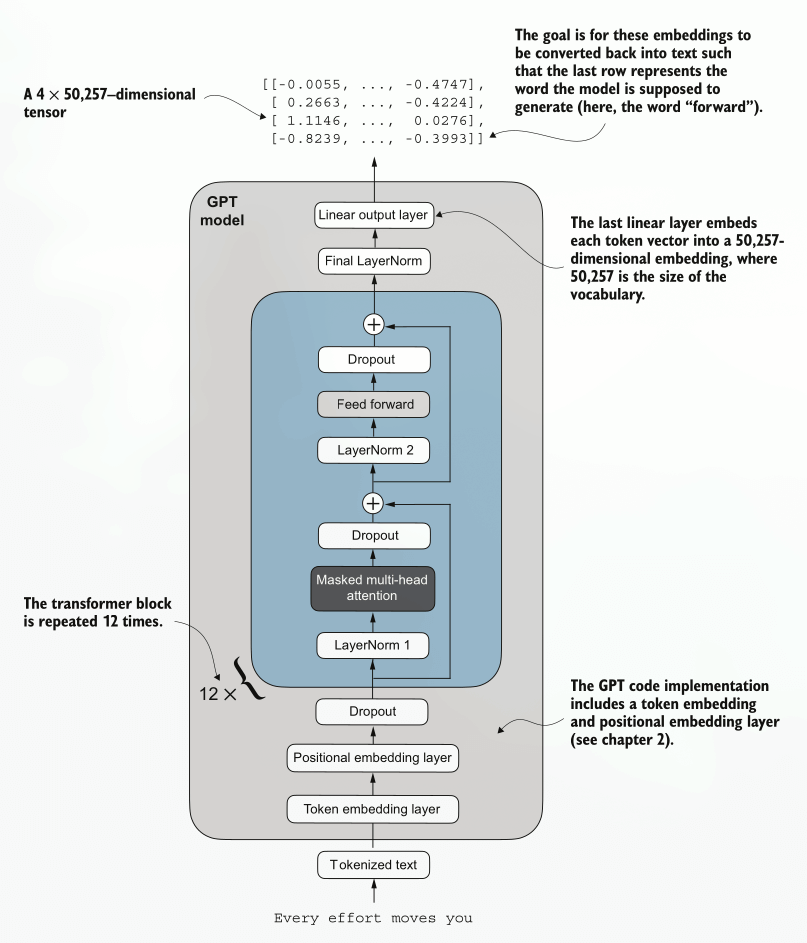
Source: Build a Large Language Model (From Scratch) by Sebastian Raschka
Flow of data throught GPT model
My understanding of the GPT model so far: what's coming in, how data flows through it, what's coming out.
- Start at the bottom. Input is text "Every effort moves you". The task of the model is to give the next word in this sequence.
- Text gets tokenized so that it's an array of numbers (tokens) instead of sentences, words or letters. Tokenization breaks text into subword units using a fixed vocabulary.
- Tokenized text is then converted into embeddings. Each token ID is looked up in an embedding matrix that turns it into a dense vector (e.g., 768 or 4096 numbers). These numbers encode a rich representation and understanding of what it is. Similar tokens end up with similar vectors.
- Then another layer of embeddings is added to encode the position of each token. The transformer has no idea of order, positional embeddings add information where each token sits in the sequence.
- Then some small % of activations are set to 0 during training (dropout) to prevent overfitting by forcing neurons to not rely too heavily on each other and to make learning more effective. This forces the network to rely on multiple pathways rather than memorizing patterns. "At each training step, I'll randomly deactivate some neurons so others learn to contribute". Dropout is used only during training, during inference it's disabled and the model uses all neurons normally.
- The combined information for this token is passed to a transformer, multiple times, to learn a little with every pass and to get closer to the desired solution. In case of GPT-2 Small model with 124 million parameters, it passes through the transformer 12 times sequentially, (for GPT-3 it's 48), with its output as input for the next iteration. Multiple passes deepen the model's ability to represent abstract relationship in text.
- For each cycle inside the transformer:
- Layer normalization. Normalizes activations for each token's vector so that features have consistent scale, improving training stability and gradient flow (loosely, gradient flow = the flow of learning towards the truth). Layer normalization stabilizes training by ensuring that each layer’s outputs have a consistent mean and variance.
- Masked multi-head attention. Each token produces Query (Q), Key (K) and Value (V) vectors, attends to previous tokens (attention = looking at all the tokens in the input and deciding which ones to focus on when processing a particular token) and aggregates context across multiple attention heads, each focusing on different aspects of relationships. Masked = looking only at previous tokens and masking the future ones, so that predictions remain causal.
- Dropout again. Randomly zeroing out a portion of activations during traing to reduce overfitting.
- Shortcut (residual) connections. What happens: adding the input of the layer to it its output (x= x + F(X)). What it means: it improves the gradient flow (the ability to learn) through the layers, so that very deeps stack remain trainable.
- Layer normalization again. Re-normalizes after the attention block to keep activations stable before feeding them into the next component.
- Feed forward network. A small two-layer neural network applied independently to each token's representation.
- Expand dimensionality (e.g. 4x, from 768 x 4 = 3072). The goal is to add more capacity to the model, resulting in more meaning and nuance.
- GELU activation. Applies smooth non-linearity to create complex transformation of features. Unlike dropout, it's used both during training and inference.
- Compress back down by 4x, to get to the same size as input, but with added learning based on the gathered context.
- Dropout again
- Shortcut (residual) connection, integrating the refined version.
- Final layer normalization. After all transformed block, a last normalization step to ensure consistent scaling of features.
- Last output layer. Maps each token's final hidden vectore to a vector the size of the tokenization vocabulary. Each position now has a set of scores: for each possible next token. All scores are converted into probabilities and the token with the highest probability is selected, completing the sequence: "Every effort moves you forward".
Scale and size of a simple GPT model
I want to see where the action happens and what percentage of the model's "horse power" is dedicated to what tasks.
Even though attention gets all the fame, most of the parameters aren't in attention at all - they are in the feed-forward networks and the embedding layers.
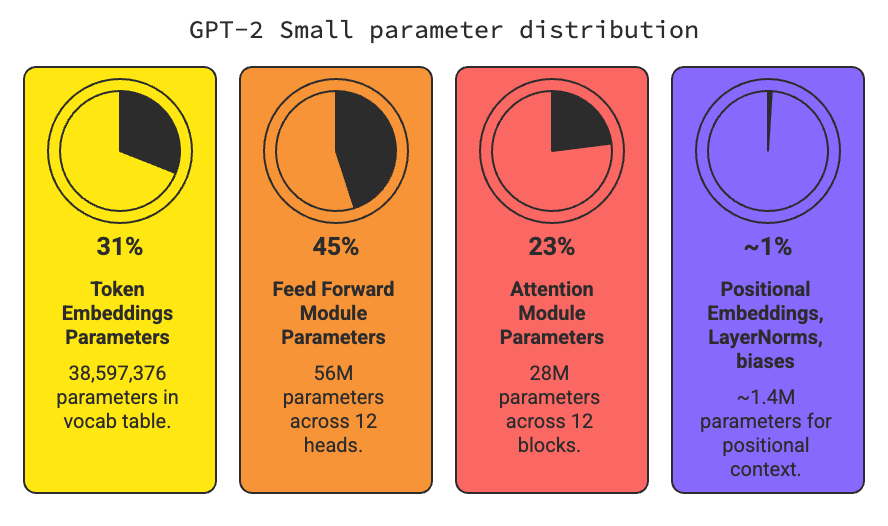
Out of 124M trainable parameters in GPT-2, how are they divided into different tasks?
GPT-2 Small (124M)
-
Total number of parameters: 163,009,536
-
Number of trainable parameters considering weight tying: 124,412,160
-
Token embeddings, essentially a huge vocab table (50,257 tokens x 768 embeddings): 38,597,376 (31%)
-
Total number of parameters in feed forward module: 4,722,432 x 12 heads = 56M (45%)
- Each head has two big linear layers:
- Up-projection: 768 × 3072 = 2.36 M
- Down-projection: 3072 × 768 = 2.36 M
- Total per block: ≈4.72 M
- Multiply by 12 layers → ~56 M parameters.
- That's nearly half the whole model!
- Each head has two big linear layers:
-
Total number of parameters in attention module: 2,360,064 x 12 blocks = 28M (23%)
- Q, K, V, O weights per layer
- Each attention block:
- W_Q weight matrix: 768 x 768 = 589,824 parameters
- W_K weight matrix: 768 x 768 = 589,824 parameters
- W_V weight matrix: 768 x 768 = 589,824 parameters
- W_O weight matrix: 768 x 768 = 589,824 parameters
- Total: 2.36M
- Attention is mostly matrix multiplications on the fly, not heavy in stored weights.
-
Positional embeddings, LayerNorms, biases: ~1.4M (~1%)
-
Total size of the model (total number of parameters x 4 bytes (float 32) per parameter): 621.83 MB
-
GPT-2XL for comparison (768 → 1,600 embeddings, 12 → 48 layers, 12 → 25 attention heads):
- Total number of parameters: 1,637,792,000
- Number of trainable parameters: 1,557,380,800
- Total size of the model: 6,247.68 MB
Attention = compute-heavy, few weights
Feed-forward = weight-heavy, cheap to run
Embeddings = giant dictionary
p. 123
Day 15 (Thu)
Started Chapter 5: Pretraining on unlabeled data
Finally finished the whole setup and scaffolding stage and getting to training and learning!
Before training, the model produces random next-token probability vectors. The goal of model training is to ensure that the probability values corresponding to the highlighted target token IDs are maximized.
Loss function. Part of the text evaluation process is to measure "how far" the generated tokens are from the correct predictions (targets). The training function uses this information to adjust the model weights to generate text that is more similar to (or, ideally, matches) the target text.
Backpropagation. Updating the model weights so that the model outputs higher values for the token IDs we want to generate. The weight update is done through backpropagation, a technique for training deep neural networks. It requires a loss function, which calculates the difference between the model's predicted output (probability of the target token's ID) and the actual desired output.
For now, without learning anything further, my understanding of what LLMs do is that it's just blind shooting in random directions, then someone is checking how far those shots were off target, then depending "how far off" the shots were, shooting either further away from the first shot or in the direction of that shot. Then repeating this process billions of times. Kind of like playing "hot and cold", abandoning dead ends and going towards "hot". Nothing else. No smart thinking, just randomness and listening to hot or cold, until it's hot enough, on enough tries.
Cross entropy loss. Essentially, this is the "how far off" number from above. It's a single number, and the larger it is, the more wrong you are. The smaller it is, the closer to the target (truth) you are getting. Mathematically, it measures the difference between two proability distributions (the one we are training and the target, correct one). Also called "negative average log probability".
Perplexity. Very similar to cross entropy, but viewed from different perspectives:
- Cross entropy - the training loss.
- Perplexity - the interpretation of that training loss. How "confused" the model is. On average, how many equally likely choices would the model have at each prediction? For example, if perplexity = 48725, this would translate to the model being unsure about which among 48,725 tokens in the vocabulary to generate as the next token, out of total 50,257 in the vocabulary, which is not great, it's shooting blind at this point. The smaller the number, the more confident it is.
p.142
Day 16 (Fri)
When preparing text for training:
- Split text into training (e.g. 90% of the text) and validation (the remaining 10%) sets
- Tokenize the text
- Divide the tokenized text into chunks of a user-specified length
- Shuffle the rows
- Organize the chunked text into batches
Why shuffle? And why batches?
- Why batches? Efficiency (parallel GPU computation) and stability (average out noisy gradients).
- Why not one-by-one? Too slow and unstable, noisy gradients (an average opinion of a group > a single opinion that could be overly-dramatic)
- Why shuffle? To prevent overfitting and make each training step see a diverse sample of text.
- Doesn't this break continuity? Yes, but only between batches, not within chunks. GPT still learns grammar and semantics just fine.
- No shuffling at inference time. The model uses actual sequential context to predict next tokens.
- In short: We batch for speed and smoother learning, and we shuffle so the model learns language in general, not the order of the dataset.
Training an LLM
A typical training loop:

Adam optimizer. Sounds cool, but it's not invented by some Adam, it's just Adaptive Moment Estimation. Adam is an optimization algorithm - the method that updates all the model's weights after each backpropagation step. Became the default optimizer for almost all deep learning tasks, including Transformers and GPT models.
AdamW. W → Weight Decay. A small improvement over Adam. Decouples weight decay from gradient updates, for better regularization. Used in all modern LLMs.
Regularization - any method that makes the model a little worse on training data so it becomes better on new data. It's the deliberate addition of constraints, noise or penalties during training to make the model simpler, smoother, or more generalizable.
Training process

For the first 1-2 epochs, training and validation sets improve (the loss decreases). Thn validation set stays stable while training set converges to 0. This divergence and the fact that the validation loss is much larger than the training loss means that the model is overfitting to the training data. It starts memorizing the training data. It works on the training data validation, but doesn't work on the validation data, which was unavailable for memorization during training.
The chart is showing such a large divergence because it was trained on a very small training dataset and it trained for multiple epochs. Usually, the models are trained on much larger datasets and only once.
p.151
Day 20 (Tue)
Temperature scaling - a technique that adds a probabilistic selection process to the next-token generation task. So it's not always the token with the highest probability that is selected, but other tokens get a chance to be selected too. The goal is minimize overfitting and to increase variability and less obvious but potentially more interesting connections. Downside: it sometimes results in grammatically incorect or even nonsensical outputs.
Top-k sampling - when combined with probabilistic sampling and temperature scaling, can improve the text generation results. In top-k sampling, we can restrict the sampled tokens to the top-k most likely tokens and exclude all other tokens from the selection process. Lets through (allows to be chosen from) only top results, preventing nonsensical connections from happening, even if rarely.
Order of operations: first top-k, then temperature scaling, then softmax to get probabilities.
Want more deterministic and strict output (e.g. for documents, reports)? Use smaller top-k values (<10) and temperature scaling <1.
Want more creative output (e.g. for brainstorming, writing fiction)? Use larger top-k (e.g. 20-40) and temperature values >1.
p.159
Day 21 (Wed)
Started Chapter 6: Fine-tuning for classification
The most common ways to fine-tune language models are instruction fine-tuning and classification fine-tuning
- Instruction fine-tuning involves training a language model on a set of tasks using specific instructions to improve its ability to understand and execute tasks described in natural language prompts. Example prompt:
Is the following text spam? "You have been selected to receive $2,000 cash today!" Answer with 'yes' or 'no'. - Classification fine-tuning is when the model is trained to recognize a specific set of class labels, such as "spam" and "not spam". Other examples: identifying different species of plants from images, categorizing news articles into topics like sports / politics / technology, or distinguishing between benign and malignant tumors in medical imaging. Example prompt:
Translate into Spanish: "Give me a cookie please"
Classification fine-tuning is done in 3 stages Classification fine-tuning is done in 3 stages
-
Stage 1: Dataset preparation
-
- Download dataset
-
- Preprocess dataset
-
- Create data loaders
-
-
Stage 2: Model setup
-
- Initialize model
-
- Load pre-trained weights
-
- Modify model for fine-tuning
-
- Implement evaluation utilities
-
-
Stage 3: Model fine-tuning and usage
-
- Fine-tune model
-
- Evaluate fine-tuned model
-
- Use model on new data
-
p.183
Day 22 (Thu)
In neural network-based language models, the lower layers generally capture basic language structures and semantics applicable across a wide range of tasks and datasets. So, fine-tuning only the last layers (i.e., layers near the output), which are more specific to nuanced linguistic patterns and task-specific features, is often sufficient to adapt the model to new tasks. It is also computationally more efficient to fine-tune only a small number of layers.
Technically, it's possible to train/fine-tune just the final output layer to modify the model so that it becomes a classifier, but training additionl earlier layers usually gets better results. For example, the last 3 items instead of the last 1:
- Last transformer block
- Final LayerNorm
- Output layer
Before fine-tuning an LLM, we load the pretrained model as a base model.
An example of a model learning well from the training data and generalizing the learning to the unseen validation data. No indication of overfitting.

How to choose the number of epochs? Depends on the dataset and the task's difficulty. 5 is a good starting point but if a model overfits after the first couple of epochs, reduce the number of epochs. If the trendline suggests that it could further improve with more training, increase the number of epochs. In the case above, 5 seems as the sweet spot: no overfitting and the validation loss is close to 0.
Same data, from accuracy perspective:

p.203
If you like what you see, you'll find more stuff like this on my Twitter.
